
































































































































































AI Accuracy Alarms: BBC–EBU Study Finds Gemini Most Error-Prone Among ChatGPT, Copilot, and Perplexity



Nearly half of all news-related responses from leading AI chat models—ChatGPT, Google Gemini, Microsoft Copilot, and Perplexity—contained false or misleading information, according to a new study by the European Broadcasting Union (EBU) and the BBC, published on Wednesday, October 22.
The research, conducted between May and June across 18 countries and 22 media organizations, compared answers from the four most popular AI assistants to identical news-related questions and evaluated their accuracy.
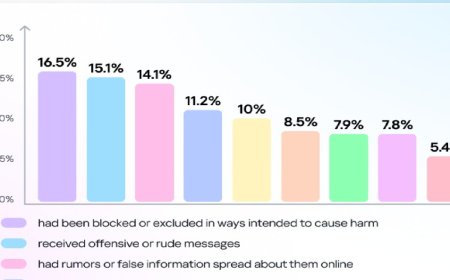
The findings revealed that 45 percent of the responses contained at least one “significant error.” The most common issue was faulty or missing source attribution, accounting for 31 percent of errors. Another 20 percent involved factual inaccuracies, while 14 percent lacked sufficient context. Among the tested models, Google’s Gemini emerged as the most error-prone, with 76 percent of its responses containing notable mistakes.
All four AI systems made fundamental factual errors. For instance, Perplexity incorrectly claimed that surrogacy is illegal in Slovakia, while ChatGPT falsely stated that Pope Francis was alive, despite reports of his passing several months earlier.
When approached for comment, OpenAI, Google, Microsoft, and Perplexity did not immediately respond to Al Jazeera’s requests.
In the report’s preface, Jean Philip De Tender, Deputy Director-General of EBU, and Pete Archer, BBC’s Head of AI, urged tech companies to take stronger steps to improve the reliability of their AI tools. They emphasized the need for transparency across languages and markets, saying: “They must regularly disclose results by language and market to ensure accountability.”
The study, which analyzed over 3,000 AI-generated responses, followed the same methodology as a BBC investigation conducted eight months earlier. Journalists participating in the review assessed the AI responses—without knowing which model had produced them—based on editorial competence and professional sourcing. Sample queries included, “What is Ukraine’s mining deal?” and “Can Donald Trump run for a third term?”
Although results showed slight improvement over the earlier BBC study, the researchers noted that major inaccuracies persist.
Commenting on the findings, Peter Archer, Director of BBC’s Generative AI Program, stated: “We care deeply about AI and how it can help us bring more value to our users—because people must be able to trust what they read, watch, and hear. Despite some continuous improvements, it’s clear that these AI assistants still have significant issues.”


















